Most of you might not know this… if the 3- to 4-year age group demographic is part of your target market, the product of choice is rainbow cakes. And maybe unicorns, but real cake trumps imaginary animals.
Now imagine satisfying a bunch of highly demanding, highly vocal, highly unpredictable, and irrational customers, on a high-stakes delivery, at the same time. SLAs be ****ed, they all want the same thing, and they all want it now. So how do you slice the
rainbow cake so you get at least a minute’s peace from the chaos? (I’m talking about a birthday party cake slicing, obviously…)
But the problem does have more relevant ramifications in the (much more manageable) world of work - as it related to data and AI adoption. Through conversations with our customers at
Instabase and helping them through their data journeys, below is a blueprint on tackling this problem.
*Note: All views are my own and not those of my employer
Banking Transformation
If you think of the transformation journey that most organisations have been on, I like to visualise it along two transformation axes:
(i) of infrastructure and (ii) of systems.
Over the last 10 years or so, we’ve seen a definitive shift in large enterprises moving their data estate from an on-premise architecture to an on-cloud architecture. Even highly regulated organisations like banks and insurance companies are now adopting
approaches that combine private and public clouds. This has been a much needed step towards making more of their data aggregated, accessible, and actionable.
The second axis is that of systems transformation — of upgrading and enhancing software systems across multiple functions and business lines within the organisation. For banks, this started with core banking systems, then came the modernisation and introduction
of SaaS for origination systems (workflow management/business process management), followed by more value added services and additions such as interaction portals, mobile interfaces and apps, e-signatures, and so on.
If one takes a step back to look at the drivers behind these transformation axes, the primary goal used to be
Process Optimisation — making the process faster, cheaper, and less error-prone. This evolved into optimising for the
Customer Journey — making the end-to-end interaction and experience of the customer more “delightful.” We are now at a stage where this driver has become optimising the
‘Data Journey’ — focusing on how information moves through the organisation and managing this data to get the most benefit from it.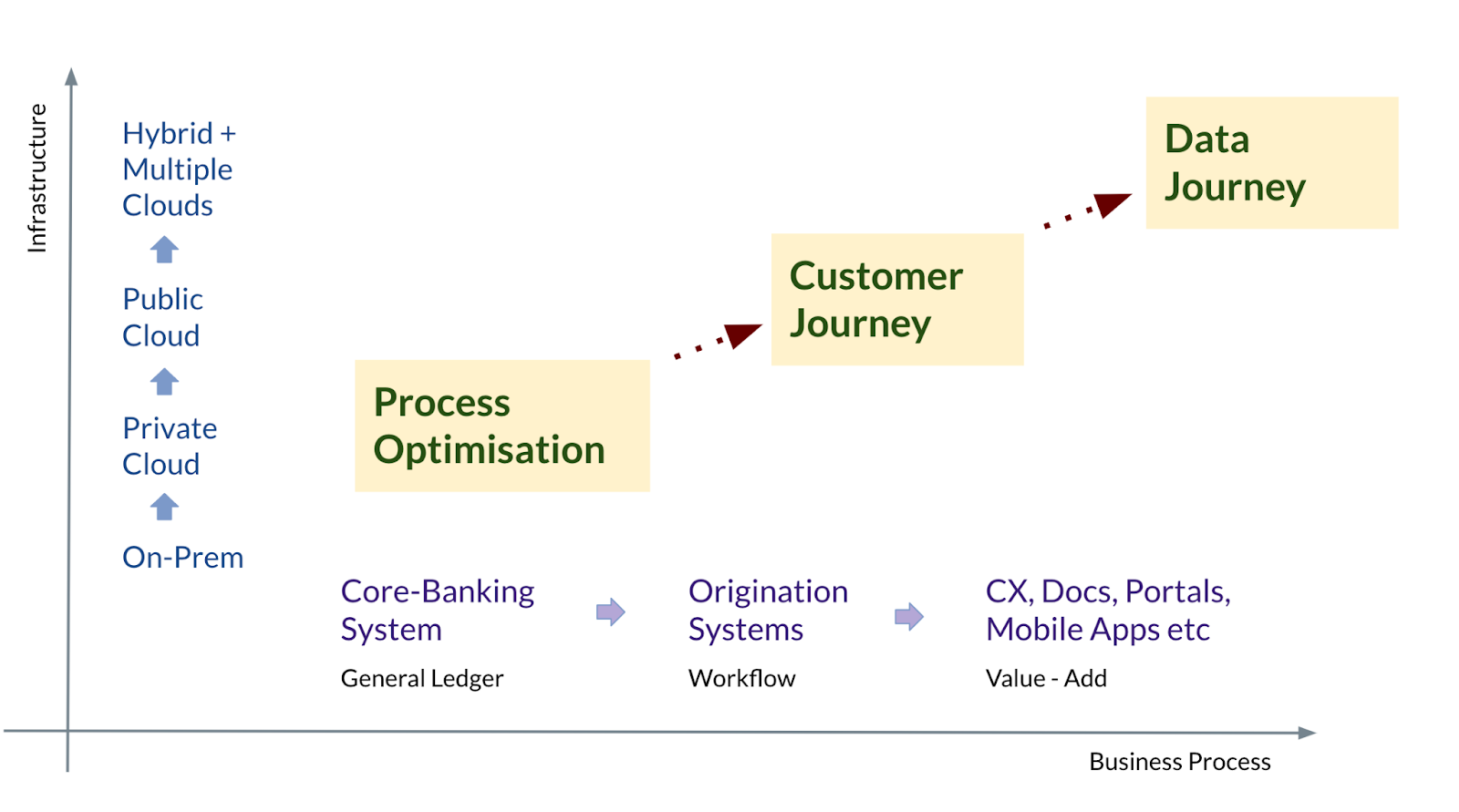
The Shift to Data Journeys
As banks shift the focus to data journeys, it is becoming increasingly obvious that this data estate itself is, to put it bluntly, a huge mess. Most organisations, especially large enterprises, have massive amounts of data flowing through their systems in
highly variable formats, following varied journeys, moving in and out across different systems. This is for business-as-usual (BAU) run time data. Stored and retained data is an even bigger challenge. Data that is stored in various different formats and various
different places, across different systems of record — different clouds, email accounts, shared drives, even yellowing paper in cardboard boxes in underground vaults.
Now, it is a truth universally acknowledged, that every single bank in possession of (good?)data must be in want of AI.*
This AI can then be used to turn that data into value — for better customer experiences, for better management of risk and generation of return, and for making most processes much faster, cheaper, and more efficient. While AI does have the potential to help
make those improvements, the actual outcomes are still predicated on one fundamental prerequisite — there needs to be good data for the AI to train on and work on. And unfortunately, until that base data is fit for purpose, all of the other goals are baseless
— mere castles in the air (with rainbows and unicorns though).
*Hence - to channel my own Jane Austen - the truth less acknowledged is that in order to access the good virtue and fortune of AI, the bank’s data needs to first be eligible.
Tidying Up Data for Automation
So where does one begin the data cleanup, with a specific focus on improving business processes? While there are a lot of ways one can slice the data cake (depending on which lens you use: geographical, storage-based, privacy-based, line-of-business related,
etc.), this one focuses specifically on when you need to get started on any kind of transformation or automation initiatives for a specific process. Note this also pertains to data stored and gathered by the organization itself (cakes your own bakery bakes),
rather than external data such as market data.
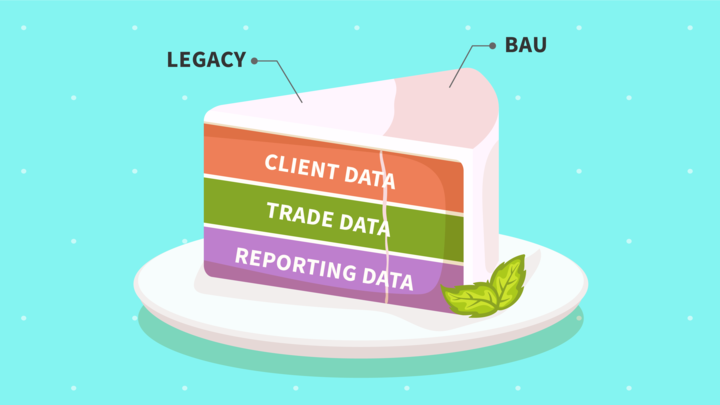
In that regard, here’s a useful way to slice the data cake:
1. Bucket any data you are working with in one of these three categories:
-
Client Data: This is data related to the customers themselves — identity data, incorporation data, specific agreements and contracts, their risk profiles, preferences, SLAs — basically anything related to Know Your Customer. This type of
data is used (i) on a forward-looking basis to recommend trades or investments, personalise advice, etc. (ii) on a run-time basis for customer service and trade execution, and (iii) on a retrospective basis for remediation, audits, and risk management.
-
Transaction Data: Or trade data, this relates to data about individual transactions or deals. This can be data in a mortgage deed, a loan agreement, a novation agreement, trade confirmation, payment instruction — anything that underscores
the obligation of each individual transaction. For example, an ISDA would be client data and a term sheet would be transaction data.This data would typically be used (ii) on a run-time basis as trades are executed, booked, and reconciled, as well as (iii)
on a retrospective basis for investigating breaks or audits, and most importantly, for risk management purposes.
-
Reporting Data: This is any data that is input into customer reporting, regulatory reporting, process monitoring or audits, as well as internal reporting and process monitoring activities. Especially for customer reporting, this data can
often include a combination of client and transaction data, as well as market data. This data would typically be used (iii) on a retrospective basis at regular intervals or (i) on a run-time basis for on-demand reporting and customised reporting, as well as
investigations of issues.
Note that while large swathes of data could fall into more than one bucket, the objective of the exercise is to have broad classifications, more from a business process perspective rather than unique and unambiguous classification from a data science perspective.
Once your data is classified into these three categories, then,
2. Bifurcate all data into legacy and ongoing.
Across all the three above horizontal data layers, split your data into two:
- Historical or Legacy Data: This is data from the past, clients onboarded in the distant past, trades already done and settled or expired, loans given out and now repaid, reports sent out that have been stored for recordkeeping, etc. Historical
data is typically stored in older, legacy systems or storage locations, potentially even hard copy data or paper documents.
-
Run-Time or BAU Data: This is data related to day-to-day activities and processes, as well as data that is expected to come in in the future. For example, clients currently active and to be onboarded going forward, trades that are still
live, outstanding loans, etc. From an automation lens, the focus here is to redesign the go-forward process in a much more efficient way, with more accessibility and connectivity across this run-time data.
Biting Off What Can Be Chewed
Now that the data in your organisation is broadly categorized, we come to the approach for process transformation or extraction automation around this. The goal to optimise towards is ideally having all your data accessible on demand and the ability to interpret,
interrogate, connect, correlate, and draw insights from all of this data.
If your driver for initiating this transformation is a non-discretionary one — for example, a regulatory deadline or a legal or compliance requirement— then by all means, go fight that fire first wherever it may be burning.
If, however, the driver is one of improvement — either to improve customer experience, manage risk better, create more operational capacity and efficiencies, or grow your revenue and business— it then helps to take a phased approach.
-
Start With Client Data: Typically, we have seen clients generate the most immediate ROI through data transformation programmes that start with client data (e.g., automating KYC processes and documents, using AI for EDD or CDD and remediation
projects, etc.). This should go across both run-time and legacy data, incorporating legacy data for a comprehensive view of each customer and of the full portfolio of customers. This then forms the bedrock of several further projects and use cases, such as
faster onboarding, personalization of products and services, improved customer service, and many more.
-
Follow With Trade Data: This is typically done with data on a forward-looking basis through automating processes such as mortgage or loan origination, termsheet creation, trade settlement, payment processing and transaction monitoring, AML
checks, etc. The focus often is reducing cycle time and minimizing errors. Automation can, more often than not, be applied in parts on legacy data and run-time data. Once the updated process is in place for any new trades, the back book of legacy trade records
can be migrated onto the same platform. However, in situations where the focus is on risk mitigation (driven either by requirements of audit, investigations or remediation) or of more efficient risk management (identifying exposures in a loan portfolio, identifying
locations of subsidiaries from a client base; etc.) — processing legacy data may become a standalone project in its own right.
-
Wrap Up With Reporting Data: Given the obligatory nature of reporting functions, most organisations will have existing processes for accessing and processing data required for reporting. More often than not though, large parts of this process
will be manual, cumbersome, and time-consuming. As a consequence, the reporting itself will not be as comprehensive, customised, and on-demand as it potentially could be. Hence the drive to automate data processing required for reporting, which can then feed
into more dynamic, tailored, and focused reporting.
- Most banks tend to come around to this segment last — choosing not to fix what might not entirely be broken. The breaks that accelerate this tend to be either issues with regulatory reporting or investigations into trades or payments (e.g., retrocession
fees for funds). If done on a proactive, discretionary basis, getting your reporting data in order could open up massively rewarding opportunities through enabling personalised reporting, which is much more accurate, comprehensive, and informative. Additionally,
imagine the value that could be created for customers, audit teams, and regulators through on-demand reporting which is focused on a particular issue and investigating a particular type of data.
Starting as You Mean to Go On:
The foregoing all relates to the initial one-off classification and approach, when embarking on any AI or automation projects based on data. However, as anyone who has tried to keep closets tidy can testify, a one-off cleanup only lasts until the next round
of laundry comes in. Hence, it is critical to set in place procedures and guidelines such that data that comes in on an ongoing basis is appropriately managed — classified, processed, and stored exactly how and exactly where it should be.
In summary:
-
Bucket your data into client, transaction, and reporting data. Bifurcate each bucket into historical and BAU data.
-
Start automation projects with client data, follow with transaction data, and wrap up with reporting data.
-
Keep any new incoming data tidy with appropriate classification and storage.
As with most other “how to” approaches in the world of transformation, there are as many ways of managing your data as there are flavours of summer ice lollies. But hopefully the above serves as a useful starting point to make some sense of the incredibly
complex, massively overwhelming yet excitingly fruitful world of enterprise data.
So take a step back from the world of data chaos and 3-year-olds’ birthday parties, and approach it through a wider lens. Remember to carry your own slice of cake with you though — you’ll want to have it and eat it too.
After all, there are very few problems in life that are not made better with a slice of cake.